5.1 DISEÑO METODOLÓGICO
El apartado de metodología debe empezar definiendo el diseño epidemiológico elegido mediante descripción de sus características o asignando un tipo de diseño modelo. El diseño metodológico es la base para planificar todas las actividades que demanda el proyecto y para determinar los recursos humanos y financieros requeridos. Esta sección se considera la más importante al elaborar un proyecto de investigación y una de las más difíciles. La pregunta que responder es ¿cómo se procederá para alcanzar los objetivos planteados? El diseño debe ser muy claro y adecuado a la pregunta de investigación. La elección de un diseño debe responder a un plan estructurado de trabajo que tiene en cuenta los objetivos del estudio y está orientado a comprobar la hipótesis de investigación y la obtención de datos que permitan abordar el problema planteado al inicio del mismo.
Cuando hablamos del diseño de un estudio nos referimos a las estrategias básicas que se adoptan para recoger y generar información exacta e interpretable, los procedimientos y métodos por los cuales se seleccionan los sujetos, se recoge y analiza la información y se interpretan los resultados, es decir, la descripción de cómo se va a realizar la investigación. Características del estudio: descriptivo/analítico; prospectivo/ retrospectivo; observacional/experimental. Tipo de diseño; estudio transversal/ estudio ecológico/estudio de casos y controles/estudio de cohortes/ensayo clínico. (Otros estudios, evaluación de pruebas diagnósticas, diagonal, revisión sistemática)
Se debe explicar no solo lo que se va a hacer y cómo, sino que debe convencer de que los métodos y los procedimientos seleccionados son los más adecuados. Se debe exponer con lujo de detalles cómo se realizará el estudio, pues ello garantiza su replicabilidad por cualquier interesado.
El abanico de posibles diseños es muy amplio y la elección depende de la hipótesis formulada y de los objetivos definidos.
La pregunta de investigación debe constituir el punto de partida para determinar la elección del diseño, pues si pretendemos “medir” una determinada característica de la población, está claro que nos orientaremos hacia un estudio de corte cuantitativo. Si por el contrario nos preocupa el efecto sobre la calidad de vida, las emociones o percepciones de los sujetos, nos estaremos orientando hacia un estudio cualitativo.
Su adecuación se determinará básicamente en función de la Validez y la Viabilidad del estudio. Se trata de evitar que un trabajo quede invalidado por la falta de un diseño correcto, que ningún análisis estadístico posterior puede salvar.
La Validez nos indicará si el diseño elegido es el adecuado para nuestra pregunta de investigación, pues no es lo mismo querer conocer los factores relacionados con la flebitis en vías periféricas, que comprobar si esta se debe a determinado tipo de apósito o catéter. En el primero podremos estudiar casos pasados, mientras que para el segundo deberemos estudiar casos futuros en un entorno controlado.
La Viabilidad tiene que ver con los recursos, conocimientos y capacidades disponibles para investigar y tienen mucho que ver con el diseño que se pretende utilizar.
El diseño de la investigación entra dentro del planteamiento metodológico y comprenderá además de la selección del tipo de estudio, la lista de variables (parámetros, test, pruebas, etc.) incluyendo su nivel de medición, el tipo de sujetos de observación, la fuente de los sujetos, el tamaño muestral adecuado y el procedimiento de observación o de intervención (si es el caso) para la toma de datos.
En la literatura científica también se denomina “material y métodos” o “procedimientos”. Deben detallarse los procedimientos, las técnicas, actividades y demás estrategias metodológicas requeridas para la investigación. Deberá indicarse el proceso a seguir en la recolección de la información, así como en la organización, sistematización y análisis de los datos.
Una vez decidido el objetivo y el diseño se han de planificar las distintas etapas del estudio elegido:
- Población y Muestra.
- Tipo de muestreo.
- Selección de variables a estudiar. Unidad de análisis.
- Criterios de inclusión y de exclusión.
- Instrumento de recolección de la información.
- Descripción de las técnicas y procedimientos a utilizar.
- Plan de tabulación y análisis.
- Recursos.
- Aspectos éticos de la investigación
Al seleccionar y plantear un diseño se busca maximizar la validez y confianza de la información y reducir al máximo posible los errores.
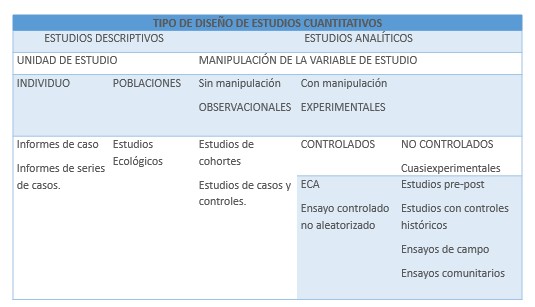
5.2 ESTUDIOS CUANTITATIVOS
El tipo de estudio y su diseño se debe seleccionar con base a los objetivos propuestos, la disponibilidad de recursos y además la aceptabilidad de tipo ético.
El investigador debe enunciar con claridad el tipo de estudio que realizará (descriptivo, experimental, observacional, etc.) y ofrecer una explicación detallada de su diseño (cohortes, casos y controles, ensayos clínicos, etc.). Se debe diferenciar si su trabajo es una investigación en la que el investigador interviene activamente tratando de introducir cambios (estudio experimental) o únicamente se limita recabar datos (estudio no experimental).
Si el diseño está concebido cuidadosamente, el producto final de un estudio (sus resultados) tendrá mayores posibilidades de éxito para generar conocimiento. Dentro del enfoque cuantitativo, la calidad de una investigación se encuentra relacionada con el grado en que apliquemos el diseño tal como fue preconcebido (particularmente en el caso de los experimentos).
5.2.1 Estudios cuantitativos
Ver descripción en tema 3
5.3 LA POBLACIÓN DE ESTUDIO
La población o universo es el conjunto de individuos u objetos de los que se desea conocer algo en una investigación. Es la totalidad de individuos o elementos en los cuales puede presentarse determinada característica que va a ser estudiada. Por lo general, no es posible abarcar a toda la población destinataria debido a su elevado número, al costo y al tiempo. En cambio, se estudia a un subconjunto de la población, a partir de la cual se extraen conclusiones (o inferencias), que se aplican a la población destinataria.
El universo debe quedar claramente identificado desde el inicio de la investigación y se debe ser específico al incluir los elementos que forman parte de ella.
En investigación, a esta población de estudio se le conoce como población diana y viene delimitada por características demográficas, sociales, hábitos, problemas de salud, etc.
Dentro de esta población diana se encuentra la población accesible o población de estudio, que es el conjunto de casos que son accesibles para el investigador. Está determinada por consideraciones prácticas en función de la accesibilidad que tengamos a los sujetos (existencia de registros, circunstancias que faciliten la colaboración, etc.). En la investigación en salud, el consultorio o el hospital puede proporcionar la población accesible. Sin embargo, esta no necesariamente representa a la comunidad, si no a todas las personas que acuden al consultorio o al hospital para el tratamiento de la enfermedad en cuestión. Esto no significa que no deban hacerse estudios realizados en el consultorio o en el hospital. Proporcionan información útil, pero los resultados no deberán presentarse como si reflejaran los correspondientes a todas las personas que padecen la afección.
La muestra es el grupo de individuos que realmente se estudiará. Para que se puedan generalizar los resultados tiene que seleccionarse de modo que sea lo más representativa posible de la población destinataria y con una cantidad suficiente para obtener respuestas válidas.
El número de individuos de la muestra normalmente se representa por n, y el número de individuos de la población por N.
5.4 LA MUESTRA
La muestra es un subconjunto o parte del universo o población en que se llevará a cabo la investigación con el fin posterior de generalizar los hallazgos. Para generalizar los hallazgos al todo, esa parte que se estudia tiene que ser representativa de la población, es decir, debe poseer las características básicas del todo.
Por ejemplo, si en la población de estudio hay un 55% de mujeres y un 45% de hombres, la muestra deberá aproximarse a esta proporción. Es evidente que la mejor forma de estar seguro de esa representatividad sería estudiando toda la población, sin embargo, esto no siempre es posible o conveniente. En el caso de estar formada por una cantidad ilimitada de unidades, la imposibilidad de estudiarlo todo surge por no conocerse su magnitud.
En general, en la investigación se trabaja con muestras y a pesar de que no hay garantía de su representatividad, hay una serie de ventajas que se pueden destacar:
- Permite que el estudio se realice en menor tiempo.
- Se incurre en menos gastos.
- Posibilita profundizar en el análisis de las variables.
- Permite tener mayor control de las variables a estudiar.
Se tendrán en cuenta los conceptos de validez interna y validez externa, pues de lo contrario queda comprometido el desarrollo del estudio.
La validez interna es la validez del propio estudio. Hace referencia a que éste no presente errores y sea desarrollado con el rigor científico necesario, que la muestra sea elegida correctamente, que los criterios de selección sean bien definidos, que sea representativa de la población y de acuerdo con un diseño apropiado.
La validez externa está relacionada con la generalización de los resultados, es decir, con la extrapolación de los resultados de la muestra a la población diana (la muestra debe, para ello, tener las mismas características que la población de origen).
La muestra a seleccionar tiene que ser representativa de esa población para poder hacer generalizaciones válidas. Se estima que una muestra es representativa cuando reúne las características principales de la población en relación con la variable o condición particular que se estudia.
La representatividad de una muestra está dada por su tamaño y por la forma en que el muestreo se ha realizado.
5.5 LOS CRITERIOS DE SELECCIÓN
Lo primero que hay que hacer es definir la unidad de análisis (individuos, organizaciones, periódicos, comunidades, situaciones, eventos, etc.). Aquí el interés se centra en “qué o quiénes”, es decir, en los participantes, objetos, sucesos o comunidades de estudio (las unidades de análisis), lo cual depende del planteamiento de la investigación y de los alcances del estudio.
Ahora bien, generalmente no toda la población accesible será válida para el estudio, por lo que los investigadores deben especificar los criterios que definen quienes deben incluirse y quiénes no. Este proceso de selección va a delimitar a la población elegible.
Los criterios de selección suelen reflejar alguno de los siguientes aspectos:
- Coste: algunos criterios reflejan restricciones de coste. Por ejemplo, el acceso a ciertos datos que pueda tener un sobrecoste o disponer de cuestionarios o materiales necesarios para el desarrollo del estudio que pueden ser costosos pueden limitar las posibilidades.
- Problemas de orden práctico: problemas para incluir a personas de difícil acceso geográfico o estado de salud.
- Posibilidad de participar en un estudio: puede ser necesario excluir de un estudio a personas que no puedan complementar un cuestionario.
- Consideraciones de diseño, ya que a veces es adecuado definir una muestra más homogénea para controlar variables extrañas.
Estos criterios, que han de especificarse en el apartado de “material y métodos” del estudio, están determinados por:
- Criterios de inclusión (criterios de elegibilidad): Deben describirse de tal manera que permitiera a una persona reproducir el estudio o juzgar si un determinado paciente estaría incluido en él. Especifican las características que la población debe tener. Suelen referirse a las características geográficas y temporales de la población accesible. Implican a veces ciertas concesiones entre los objetivos científicos y los prácticos. Sobre estas y otras decisiones acerca de los criterios de inclusión no hay un solo modo de acción que sea claramente acertado. Lo importante es tomar decisiones sensatas, que quepa utilizar de manera consistente a lo largo del estudio y que proporcionen una base para conocer a quién se le aplica las conclusiones publicadas.
- Criterios de exclusión: deben definirse a priori, define características que sus miembros no deben tener, es decir, indican subgrupos de personas que serían adecuados para la pregunta de investigación si no fuera por características que podrían interferir en el seguimiento, la calidad de los datos o la posibilidad de aceptar la intervención. Una buena norma que preserva el número de posibles participantes en el estudio es tener tan pocos criterios de exclusión como sea posible, debemos tener en cuenta que estos criterios pueden condicionar la aplicabilidad práctica de los resultados del estudio, ya que pueden cuestionar la representatividad de la muestra de estudio.
5.6 EL MODELO DE SELECCIÓN DE LA MUESTRA
Existen dos grandes tipos de muestreo. Cada uno de ellos ofrece varias formas de extraer muestras de una población. Los dos tipos de muestreo son el Muestreo Probabilístico y el Muestreo No Probabilístico.
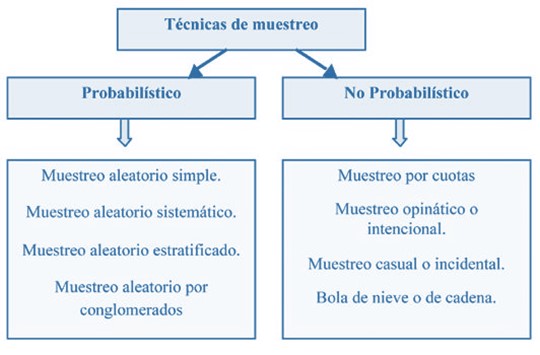
5.6.1 Muestreo probabilístico
En el muestreo probabilístico, aleatorio o randomizado, la muestra es aquella extraída de una población de tal manera que todo miembro de ésta tenga una probabilidad conocida de estar incluido en la muestra. Por lo tanto, conocemos la probabilidad de que un individuo sea elegido para la muestra.
El modelo de selección de la muestra más eficaz es el muestreo probabilístico, en el que cada unidad de muestreo tiene una probabilidad conocida de ser incluido en el estudio. Nos indica cuál es el error de muestreo y dentro de estos el muestreo estratificado es el más preciso.
Los principales tipos de muestro probabilístico son:
- Muestreo aleatorio simple (MAS). Es el más sencillo, eficaz y usado. Otorga a todos los sujetos de una población la misma probabilidad de ser incluidos en la muestra. Tras haber asignado un número a cada sujeto, se utilizan números aleatorios para la obtención de la muestra. Son seleccionados por sorteo o mediante una tabla de números aleatorios que puede ser en formato papel, pero normalmente son generados por ordenador y se utilizan las tablas que incluyen los programas informáticos estadísticos (o la función “ALEATORIO.ENTRE” de la hoja de cálculo Excel® de Microsoft). Este procedimiento es simple y eficaz, pero tiene un inconveniente, ya que no se puede utilizar si el universo es muy grande.
- Muestreo aleatorio sistemático. Este procedimiento exige, como el anterior, numerar todos los elementos de la población, pero en lugar de extraer n números aleatorios, sólo se extrae uno. Se parte de este número aleatorio i. Los elementos que integran la muestra son los que ocupan los lugares i, i+k, i+2k, i+3k. ...
El riesgo de este tipo de muestreo está en los casos en que se dan periodicidades en la población, y sólo obtengamos representantes de una clase o proporciones distintas en la muestra de la que realmente tienen en la población. Esta situación comprometería la representatividad de la muestra. - Muestreo aleatorio estratificado. Se divide la población en diferentes estratos (grupos homogéneos de sujetos) y se hace un muestreo aleatorio simple dentro de cada estrato, de forma que en la muestra queden representados todos los segmentos que nos interesen. Por ejemplo, si en una población muy heterogénea en cuanto a edad interesa que todos los grupos de edad estén representados, la solución es realizar un muestreo aleatorio simple dentro de cada grupo de edad. A la hora de necesitar este tipo de muestreo, conviene tener en cuenta no hacer muchos estratos y no estratificar con respecto a muchas variables.
- Muestreo por conglomerados. Simplifica el muestreo cuando una población está agrupada en conglomerados (localidades, edificios, manzanas). Se utiliza cuando no se cuenta con un listado detallado de las unidades de la población, y/o se tiene dificultad de organizar las unidades muestrales. En estas circunstancias no podemos utilizar el muestreo estratificado. Por ello se procede a formar grupos o conjuntos de unidades (conglomerados) que los investigadores definen. Se puede elegir a la totalidad de los individuos de un conglomerado o a una muestra aleatoria simple del mismo. Este tipo de muestreo es el menos fiable.
5.6.2 Muestreo no probabilístico
En el muestreo no probabilístico, “muestreo por conveniencia” o no aleatorio, no se conoce esa probabilidad, y por lo tanto la posibilidad de que existan sesgos es mayor. Eso implica, entre otras cosas, que en principio no se pueden extrapolar los resultados a la población. A pesar de ello, en ocasiones no queda otra elección que utilizarlos.
- Muestreo por cuotas. También denominado en ocasiones “accidental” (no confundir con el muestreo incidental). Se asienta sobre la base de un buen conocimiento de los estratos de la población y/o de los individuos más “representativos” o “adecuados” para los fines de la investigación. Mantiene, por tanto, semejanzas con el muestreo aleatorio estratificado, pero no tiene el carácter de aleatoriedad de aquél. En este tipo de muestreo se fijan unas cuotas que son un número de individuos que reúnen unas condiciones determinadas. Una vez determinada la cuota se eligen los primeros que se encuentren que cumplan esas características. Es el método de elección en las encuestas de opinión. Por ejemplo, necesitamos 120 individuos adictos a drogas de 25 a 40 años, de sexo femenino y residentes en Madrid. Los servicios sociosanitarios de la Comunidad de Madrid proporcionan un listado por núcleos de residencia con todos los sujetos de la Comunidad distribuidos que reúnen esos criterios. Por último, se escogen los primeros de cada listado hasta completar los 120 sujetos que necesitamos.
- Muestreo opinático o intencional. Este tipo de muestreo se caracteriza por un esfuerzo deliberado de obtener muestras “representativas” mediante la inclusión en la muestra de grupos supuestamente típicos. Es muy frecuente su utilización en sondeos preelectorales de zonas que en anteriores votaciones han marcado tendencias de voto.
- Muestreo casual o incidental. Se trata de un proceso en el que el investigador selecciona directa e intencionadamente los individuos de la población. El caso más frecuente de este procedimiento el utilizar como muestra los individuos a los que se tiene fácil acceso (los profesores de universidad emplean con mucha frecuencia a sus propios alumnos) o el caso particular de los voluntarios.
- Cadena o bola de nieve. Se localiza a algunos individuos, los cuales conducen a otros, y estos a otros, y así hasta conseguir una muestra suficiente. Este tipo se emplea frecuentemente cuando se hacen estudios con poblaciones “marginales”, delincuentes, sectas, pacientes de difícil localización por su “marginalidad”, etc.
5.6.3 Asignación a los grupos de estudio
La asignación de los individuos a los diferentes grupos debe asegurar la comparabilidad de los grupos, es decir, que no haya diferencias entre las variables generales.
La asignación según el tipo de estudio es:
- Estudios de casos y controles. La asignación se realiza en función de la existencia o no de enfermedad.
- Estudios de cohortes. La asignación se realiza en función de la presencia o no de exposición al factor de riesgo.
- Estudios experimentales. La más utilizada es la asignación aleatoria o randomización.
5.7 TAMAÑO DE LA MUESTRA
La determinación del tamaño de la muestra tiene por objeto conocer cuál es el número mínimo de sujetos o unidades de análisis necesarias para nuestro propósito. Por lo tanto, el tamaño muestral hace referencia al número de elementos de la población que hay que seleccionar para extraer de ella la información que después se va a generalizar. Según Fisher, el tamaño de la muestra debe definirse partiendo de dos criterios:
- Los recursos disponibles, que fijan el tamaño máximo de la muestra. La recomendación es siempre tomar la muestra mayor posible. La lógica nos indica que entre más grande sea esta, mayor posibilidad tendrá de ser más representativa y menor será el error de muestreo, el cual siempre existe.
- Los requerimientos del plan de análisis que fija el tamaño mínimo de la muestra. El tamaño de la muestra deberá ser suficiente para permitir un análisis confiable de los cruces de variables, para obtener el grado de precisión requerido en la estimación de proporciones, y para probar si las diferencias entre proporciones son estadísticamente significativas. Esto significa que al momento de decidir el tamaño de la muestra es necesario tener presente el tipo de cuadros que se elaborarán y las técnicas estadísticas que se emplearán.
Cuando se hace una muestra probabilística, los investigadores deben preguntarse sobre el número mínimo de unidades de análisis (personas, organizaciones, historias clínicas, etc.), que necesito para conformar una muestra (n) que me asegure un error estándar aceptable fijado por el equipo investigador, dado que la población N es aproximadamente de tantos elementos.
Cuanto más homogénea sea la población, su varianza (variabilidad) será más pequeña y por lo tanto, el tamaño maestral que tenemos que elegir será menor. También, a mayor nivel de confianza y precisión (menor error muestral tolerado), más muestra será necesaria. Varianza, nivel de confianza y error muestral están directa y positivamente relacionados.
El tamaño de la muestra variará en función del método de muestreo escogido, dependiendo la elección de la finalidad (que vendrá determinada por los objetivos). Se utilizarán diferentes fórmulas si se pretende estimar una proporción, estimar una media, comparar dos proporciones y comparar dos medias. Al hacer el cálculo final del tamaño de la muestra, deben tenerse también en cuenta los factores como los abandonos, el desgaste y las pérdidas en el seguimiento.
Para calcular el tamaño tenemos que conocer si tratamos de poblaciones finitas o infinitas. La tendencia de los investigadores que se inician es querer aplicar una fórmula que indique cuál será el número de sujetos que deben incluir en la muestra. Sin embargo, no es esto lo más importante. Una muestra, probabilística o no, dependerá de muchos aspectos como los recursos disponibles, la heterogeneidad de las variables y sujetos a estudiar, la técnica que se emplee en el muestreo, el tipo de análisis que se utilizará, el grado de precisión que deben tener los datos, entre otros.
Existen en la web varias calculadoras y programas para calcular la muestra:
- Fisterra(descarga): https://www.fisterra.com/mbe/investiga/9muestras/tamano_muestral.xls
- Epi Info 3.5.4 es un programa de software gratis del dominio público desarrollado por los Centros para el Control y la Prevención de Enfermedades de los Estados Unidos (CDC) descarga gratuita aquí: https://www.cdc.gov/epiinfo/esp/es_index.html
- Programa online gratuito GRANMO
5.8 ERRORES EN LOS ESTUDIOS EPIDEMIOLÓGICOS
Todo estudio epidemiológico es entendido como un ejercicio de medición, en el que debe perseguirse la exactitud, esto es, la estimación del parámetro deseado con el mínimo error. Siempre se debe perseguir es que el estudio sea preciso y válido, pero todo estudio epidemiológico está sujeto a un cierto margen de error, por lo que será muy importante conocer cuáles son sus fuentes principales y los diferentes procedimientos que pueden ser utilizados para minimizar su impacto en los resultados.
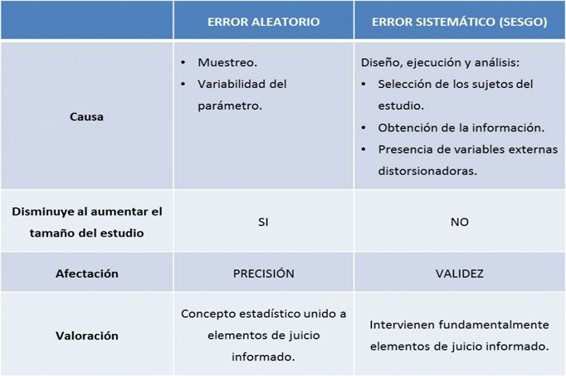
Existen dos posibles fuentes de error, el error aleatorio y el error sistemático. Un estudio es preciso cuando carece de error aleatorio y es válido cuando carece de error sistemático.
La analogía que se utiliza para describir ambos conceptos es la práctica del "tiro al blanco" donde el punto medio del objetivo es el valor verdadero en la población blanco y los "disparos" son las diferentes mediciones que se realizan en la población en estudio para estimar dicho valor verdadero. Un buen tirador cuya arma no está bien calibrada apuntará al blanco equivocado, podrá ser muy preciso (todos los disparos dan en el mismo lugar), pero ninguno de ellos da en el blanco correcto. Esto corresponde al error sistemático. Por otra parte, un tirador con mano temblorosa, pero con un arma bien calibrada, estará apuntando al blanco correcto aun cuando sus disparos no den en el punto medio del blanco seleccionado, esto correspondería al error aleatorio.
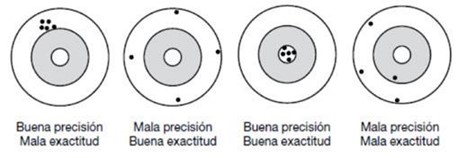
En estudios epidemiológicos validez es sinónimo de exactitud
y fiabilidad sinónimo de precisión
Por error aleatorio (debido al azar) entendemos el error ligado al propio proceso de medición, esto es, a la falta de precisión: tendremos un valor distinto, e impredecible dentro de un rango en cada una de las repeticiones de la medición. La variabilidad de una medición será por tanto un indicador de su precisión, cuanto más amplia sea dicha variabilidad menor será su precisión. Esta variabilidad puede ser debida a distintos factores como son la variabilidad biológica, la imprecisión del instrumento de medida, la inexperiencia del evaluador, etc.
Los errores aleatorios no suelen afectar a la validez interna de los estudios (no alteran la dirección de los resultados), pero sí limitan su potencia. En un estudio epidemiológico, la manera principal de reducir el error aleatorio consiste en aumentar el tamaño de la muestra. De esta manera, minimizamos el riesgo de obtener resultados distorsionados por azar, ya que la repetición de la medición tenderá a producir resultados distintos pero cercanos al valor verdadero del parámetro a medir.
Asumiendo que la repetición de un experimento con un mismo número de pacientes puede dar resultados diferentes por mero azar, la inferencia estadística nos permite cuantificar el rango de error, a partir de medidas de dispersión de los resultados obtenidos y del tamaño muestral (error estándar). A menor dispersión de los resultados y mayor tamaño muestral tendremos menor rango de error. El rango de error de nuestra estimación puede expresarse como un intervalo de confianza, situado entre un valor por debajo y otro por arriba del resultado obtenido. Cuanto más grado de confianza queramos atribuir a nuestra estimación de error, más amplio será el rango de dicho intervalo. Habitualmente empleamos el intervalo de confianza al 95%.
Por error sistemático entendemos la falta de validez en la medición. También se le denomina sesgo. La validez se refiere al concepto de "medir lo que se quiere realmente medir". La validez es la carencia de error sistemático. El error sistemático es atribuible a errores metodológicos que, a diferencia del error aleatorio, no se reducen aumentando el tamaño muestral.
La validez de un estudio de investigación suele distinguir entre dos conceptos: validez interna y validez externa.
- Por validez interna se entiende la propiedad de que los resultados del estudio son válidos entre los propios sujetos del estudio. Por otra parte, la existencia de validez interna es un requisito previo para que pueda darse la validez externa.
- Por validez externa se entiende la capacidad de generalización de los resultados, es decir, la capacidad de extender y aplicar las inferencias obtenidas a partir de ellos a una población diana (o población objetivo, también llamada externa) de referencia.
Podemos clasificar los sesgos, en sesgos de selección, sesgos de información (o clasificación) y sesgos de análisis (confusión e interacción).
5.8.1 Sesgos de selección
- Existe un sesgo de selección cuando se produce una distorsión del efecto estimado como consecuencia de errores en el proceso de selección de los sujetos. Si la elección de los grupos a comparar no es apropiada se producirá un sesgo de selección. Es un sesgo que se comete con frecuencia en los estudios caso-control y ante el que se debe estar especialmente alerta. Estos sesgos se pueden cometer:
o Al seleccionar el grupo control.
o Al seleccionar el espacio muestral donde se realizará el estudio.
o Por pérdidas en el seguimiento.
o Por la presencia de una supervivencia selectiva.
Son ejemplos de sesgo de selección:
- Sesgo de autoselección. La inclusión de sujetos voluntarios puede hacer que la población no esté debidamente representada en la muestra, pueden hacerlo por factores que pueden influir con la relación que se estudia.
- Falacia de Berkson. Ocurre en los estudios casos-control cuando los controles se seleccionan entre sujetos hospitalizados ya que en los sujetos expuestos al factor de riesgo aumentaría el riesgo de ser ingresados.
- Falacia de Neyman o falacia de supervivencia. Ocurre en los estudios casos-control cuando la exposición está muy relacionada con la supervivencia. Cuando la enfermedad produce muertes precoces, los sujetos no expuestos, al ser los que sobreviven son los que se incluyen en el estudio, y por eso puede parecer que tienen mayor prevalencia que los expuestos.
- Sesgo de membresía o pertenencia. Puede ocurrir cuando se trabaja con grupos preexistentes, es decir, grupos no formados de manera aleatoria, como ocurre por ejemplo en el caso de estudios cuasiexperimentales.
- Sesgo del trabajador sano. Este sesgo se identificó cuando los trabajadores sometidos a ambientes peligrosos parecían tener tasas de supervivencia mayores que las de la población general. Lo que en realidad sucede, es que precisamente se requiere una buena salud para poder trabajar en esos ambientes (algo que no ocurre en la población general), no que la exposición a ambientes peligrosos proteja a los trabajadores.
5.8.2 Sesgos de información o clasificación
- Los sesgos de información o clasificación consisten en la distorsión del efecto estimado por errores en la medición y/o clasificación de los sujetos en una o más variables. Algunos ejemplos son los instrumentos de medición no válidos o no calibrados, criterios diagnósticos inapropiados o cambiantes, pérdidas de información, seguimiento desigual entre los grupos de estudio, inconsistencia entre los entrevistadores, ausencia de interpretación ciega de la exposición o del efecto, etc. La influencia de estos errores en la clasificación del nivel de exposición o en el efecto puede distorsionar nuestros resultados, especialmente cuando los errores sean diferenciales.
o Entendemos por error de clasificación diferencial, el producido cuando el criterio de clasificación en uno de los grupos que se comparan es diferente del criterio utilizado en el otro grupo. El efecto de este error suele traducirse en que los sujetos de un grupo sean clasificados incorrectamente y los del otro correctamente. La estimación del efecto puede verse aumentada o disminuida, produciéndose una distorsión en contra o a favor de la hipótesis nula.
o El error de clasificación no diferencial es el cometido cuando se clasifica incorrectamente a los dos grupos por igual. La clasificación de exposición o de enfermedad es errónea para iguales proporciones de sujetos en los dos grupos de comparación. Este error tiende a producir una subestimación del efecto, esto es, una distorsión a favor de la hipótesis nula y en consecuencia genera resultados más conservadores. Por ello, el error no diferencial ocasiona menos problemas que el error diferencial.
Otros ejemplos de sesgo de información:
- Sesgo de memoria (recall-biass). Ocurre en los estudios casos-control, donde la información se recoge retrospectivamente y el sujeto puede haber olvidado aspectos relativos a la exposición o relevantes para el factor de estudio. Este sesgo es más frecuente en los sujetos sanos (controles), porque los que presentan la enfermedad (casos) pueden recordar mejor la exposición si esta les originó un cuadro agudo.
- Efecto Hawthorne o sesgo de atención. Es un tipo de sesgo de información que puede ocurrir al no tener grupo control. Se produce cuando al saber los participantes que están siendo observados, alteran su comportamiento.
o Sesgo del entrevistador. El entrevistador puede emplear preguntas o frases que condicionen la respuesta del individuo. - Sesgo de deseabilidad social u obsequiosidad. Ocurre cuando los participantes orientan sus respuestas para dar una buena imagen de sí mismos al entrevistador, de modo que los encuestados pueden modificar la respuesta que realmente refleja sus sentimientos u opiniones a favor de la que se considera más positivamente valorada.
- Sesgo de respuesta invariable. Ocurre por la tendencia del individuo a responder siempre de la misma manera.
- Sesgo de aprendizaje o proximidad. Sucede al aplicar en más de una ocasión el mismo instrumento de medida. Se minimiza dejando pasar al menos 6 meses entre una medición y otra.
- Sesgo de falseamiento. Ocurre cuando de forma premeditada o inconsciente, los participantes dan respuestas falsas o incompletas a preguntas consideradas íntimas o traumáticas.
- Sesgo de cuestionario. Aparece si el cuestionario no está correctamente diseñado y contiene preguntas ambiguas.
- Sesgo de no respuesta. Aparece debido al abandono o fallecimiento de los sujetos que participan en el estudio.
5.8.3 Sesgos de análisis
- Sesgos de análisis pueden ser controlados en la fase de análisis. De estos sesgos de análisis los principales son la confusión y la interacción.
5.9 FACTOR O VARIABLE DE CONFUSIÓN
Cuando el efecto estimado de la relación exposición-enfermedad está distorsionado por la presencia de algún factor extraño en el análisis de los datos, decimos que existe confusión. El estimador del efecto de interés está distorsionado por estar mezclado con el efecto producido por un factor extraño que llamamos factor o variable de confusión. La presencia de tal factor de confusión altera los resultados y puede producir un aumento o disminución del efecto, o incluso cambiar la dirección del mismo.
Para que un factor sea de confusión necesita cumplir unos requisitos:
- O debe ser un factor de riesgo independiente de la enfermedad tanto para los expuestos como para los no expuestos en la población.
- O debe estar asociado al factor de exposición que estudiamos en la población de donde provienen los casos.
- O no debe ser una consecuencia de dicha exposición, es decir, no ser un paso intermedio en la cadena o secuencia de causalidad entre la exposición y la enfermedad.
Un sesgo de confusión puede corregirse previamente al inicio del estudio durante su diseño, empleando técnicas de restricción, pero también puede corregirse en el análisis, mediante técnicas de ajuste. Hablamos fundamentalmente del análisis estratificado y del análisis multivariante.
DIFERENCIAS ENTRE ERROR ALEATORIO Y ERROR SISTEMÁTICO
BIBLIOGRAFÍA
- Asociación Médica Mundial.Declaración de Helsinki de la Asociación Médica Mundial. Principios éticos para las investigaciones médicas en seres humanos. Anales del Sistema Sanitario de Navarra. 2008; 24(2):209-212.
- Casado M., Vilà A. Declaración Universal sobre Bioética y Derechos Humanos de la Unesco y la discapacidad, 1ª ed. Barcelona: Edicions Universitat Barcelona; 2014.
- Consejo de Organizaciones Internacionales de Ciencias Medica. International Ethical Guidelines for Biomedical Research Involving Human Subjects. Ginebra: CIOMS; 2002
- Sinobas P E. Manual de investigación cuantitativa para enfermería. Oviedo: Federación de Asociaciones de Enfermería Comunitaria y Atención Primaria; 2011.
- Fathalla Mahmoud F. Guía práctica de investigación en salud. Vol. 620. Washington DC: Organización Panamericana de la Salud, 2008. 247 p.
- Galindo-Domínguez, H. Estadística para no estadísticos: una guía básica sobre la metodología cuantitativa de trabajos académicos. 1ªed. Alicante:3ciencias, 2020. DOI: https://doi.org/10.17993/EcoOrgyCso.2020.59
- Grupo de trabajo sobre GPC. Elaboración de Guías de Práctica Clínica en el Sistema Nacional de Salud. Actualización del Manual Metodológico. Madrid: Ministerio de Sanidad, Servicios Sociales e Igualdad; 2016
- Hernández Sampieri R, Fernández Collado C BLP. Metodología de la investigación. 5a ed. México, D.F: McGraw-Hill; 2010. 613 p.
- Mirón Canelo JA, Alonso Sardón M I. Metodología de investigación en Salud Laboral. Med y Segur del Trab. 2010;56(221):347–65.
- Instituto Aragonés de Ciencias de la Salud. Manual Metodológico. Madrid: Plan Nacional para el SNS del MSC.
- Instituto Aragonés de Ciencias de la Salud-I+CS; 2016.
- Ochoa Sangrador C., Molina Arias M., Ortega Páez E. Inferencia estadística: contraste de hipótesis. (Internet) Evid Pediatr, 2020; 16:11. Disponible en: https://evidenciasenpediatria.es/articulo/7537/inferencia-estadistica-contraste-de-hipotesis (consultado 20 agosto 2024)
- Parreño Urquizo A. Metodología de investigación en salud. Instituto de Investigaciones. Riobamba: Escuela Superior Politécnica de Chimborazo; 2016.
- Pita Fernández, S. Epidemiología. Conceptos básicos. En: Tratado de Epidemiología Clínica. Madrid; DuPont Pharma, S.A.; Universidad de Alicante: 1995.
- Royo Bordonada M.Á, Damián Moreno J. Método epidemiológico. Madrid: ENS Instituto Salud CarlosIII;2009.
- Salamanca Castro AB. El AEIOU de la investigación. Enero 2013. Madrid: FUDEN; 2013. 494 p.
- Vicente Edo, MJ., Gavín Benavent, P., Cantero Muñoz, P., Novella Arribas, B., Reviriego Rodrigo, E., Toledo Chávarri, A., Triñanes Pego, Y. Evaluación de Tecnologías Sanitarias. Material de Formación para Pacientes y Ciudadanía. Versión completa. Madrid: Ministerio de Sanidad; Zaragoza: Instituto Aragonés de Ciencias de la Salud; 2020. 113 p.