6.1 ESTADÍSTICA INFERENCIAL
Los investigadores deberán interrogarse si los resultados del estudio podrían generalizarse más allá del tamaño relativamente pequeño de la muestra estudiada. Esto se denomina validez o capacidad de generalización externa.
La estadística nos ayuda a hacer inferencias. Una inferencia es una generalización que se hace acerca de una población a partir del estudio de un subconjunto o muestra de esa población. Una población contiene normalmente demasiados individuos para estudiarlos con comodidad, muchas veces, la investigación está restringida a una o más muestras extraídas de ella. Debe recalcarse que si la muestra de estudio no es representativa de la población, la inferencia que nosotros obtenemos del resultado será engañosa. La estadística analítica no será de ninguna utilidad si la muestra no es representativa. La estadística analítica no puede corregir nuestros errores en el diseño del estudio.
Con todo, incluso con muestras seleccionadas adecuadamente, los resultados de una única muestra están sujetos a cierto grado de incertidumbre o azar. Este error de muestreo no puede eliminarse completamente, pero puede calcularse su magnitud.
De forma general se distinguen dos grandes categorías de métodos de inferencia:
- Métodos para estimación de parámetros poblacionales, que puede ser puntual o por intervalos.
- Métodos para contraste de hipótesis. Se formula la hipótesis nula (H0) y se contrasta con los datos obtenidos en la muestra, para saber si la hipótesis nula es verdadera (en ese caso, se acepta la H0) o falsa (en tal caso, se rechaza la H0).
6.2 ERROR ESTÁNDAR
El error estándar (EE) es una medida estadística acerca de la probabilidad de que el resultado en la muestra refleje el resultado de la población. El error estándar depende de dos factores, el tamaño de la muestra y las variaciones de las mediciones en la muestra, indicadas por la desviación estándar. Por ejemplo, el error estándar de una media se calcula como la desviación estándar dividida entre la raíz cuadrada del número de observaciones.
Por sí solo, el error estándar puede tener un significado limitado, pero puede usarse para obtener un intervalo de confianza que tiene una interpretación útil. En pocas palabras, se ha calculado que la media de la muestra, más o menos 1,96 veces su error estándar, da el intervalo de confianza de 95%, lo que significa que hay una probabilidad de solo 5% de que este intervalo no incluya la media de la población
El error estándar (EE) puede calcularse no solo sobre una media, sino también sobre la diferencia entre dos medias, sobre un porcentaje, sobre una diferencia entre dos porcentajes y sobre un coeficiente de correlación.
6.3 PRUEBA DEL CONTRASTE DE HIPÓTESIS
El objetivo del contraste de hipótesis es permitir generalizaciones de los resultados de nuestra muestra a la población de la que procede. Cuando el resultado de un estudio, en el que se comparan varias alternativas, muestra diferencias, el siguiente paso es estimar si dichas diferencias corresponden a diferencias reales en la población o pueden ser explicadas por azar.
Si la probabilidad de que el resultado obtenido se deba al azar es muy baja, podremos asumir que corresponda a una diferencia real en la población, aunque siempre existirá una cierta probabilidad de error. Esta probabilidad será tanto más baja cuanto mayor sea la diferencia encontrada y más grande el tamaño muestral.
Los contrastes de hipótesis sobre parámetros, son recursos de inferencia estadística que partiendo de la formulación de dos hipótesis contrarias sobre el posible valor de un parámetro (o de una expresión de varios parámetros), permiten pronunciarse acerca de la veracidad de una de ellas.
El contraste de hipótesis se plantea habitualmente bajo el supuesto de 2 hipótesis contrapuestas, una hipótesis nula conservadora que sostiene la ausencia de diferencias (por ejemplo el porcentaje de curación con el nuevo tratamiento es igual al que se obtiene con un tratamiento clásico), frente a una hipótesis alternativa novedosa que defiende la existencia de diferencias (por ejemplo el porcentaje de curación con el nuevo tratamiento es mayor). Para poder aceptar la hipótesis alternativa debe rechazarse la hipótesis nula, lo cual se consigue cuando la diferencia o efecto encontrado en el estudio no parece debido al azar.
El uso de la hipótesis de nulidad en la labor científica se ha comparado con el proceso judicial de suponer la inocencia hasta que se demuestre lo contrario (Browneret al., 2001). En esa misma línea de razonamiento, pueden cometerse dos tipos de errores en la prueba de la hipótesis de nulidad en la metodología de investigación, y la determinación estadística de si el resultado pudiera deberse al azar.
- El primero es cuando rechazamos la hipótesis nula y esta es cierta. Esto es similar al error en el proceso judicial de rechazar la inocencia y condenar a un acusado inocente. En el idioma estadístico, esto se conoce como error de tipo I.
- La imposibilidad de rechazar la hipótesis nula cuando no es verdadera se denomina error de tipo II. En el proceso judicial, esto sería similar a no lograr la condena de un acusado que en realidad es culpable.
Diversos procedimientos estadísticos (basados en los datos del estudio y en el tamaño muestral) nos permiten calcular la probabilidad de que dicho resultado se produzca por azar. Por convención, si esta probabilidad es menor del 5% (p<0,05) se considera que no se debe al azar, en ese caso se rechaza la hipótesis nula y se acepta la alternativa. En los programas informáticos (SPSS, Epi Info, EPIDAT, etc.) en el resultado aparecerá que p y no se debe al azar.
Si la probabilidad de que los resultados sean debidos al azar es mayor (p≥0,05), en estos casos el contraste de hipótesis no permite rechazar la hipótesis nula. En la mayoría de los programas informáticos en el resultado aparecerá p > 0.05 o 0.01, la diferencia no es estadísticamente significativa.
Esta decisión se tomará asumiendo siempre cierto margen de error, equivalente a la probabilidad anteriormente calculada (error tipo I; alfa) La probabilidad de cometer un error de tipo I: el rechazo de la hipótesis de nulidad cuando en realidad es verdadera o la demostración de una asociación cuando no existe ninguna.
Otro nombre de alfa es la magnitud de la significación estadística y es expresada en el valor “p” de significación. No obstante, el valor “p” no ilustra de la magnitud de los resultados obtenidos, como si lo hace el intervalo de confianza. Su nivel de significación, arbitrariamente elegido, va a verse muy influido por el tamaño de la muestra, al margen de cuál sea el efecto encontrado. Por ello va a ofrecer poca información sobre la relevancia clínica de los resultados.
Se pueden encontrar cifras mayores del 5% porque la diferencia real en la población sea pequeña, en cuyo caso no cometeremos ningún error, o bien porque hayamos obtenido una diferencia muy pequeña por azar, en cuyo caso estaremos cometiendo un error (error tipo II, beta). La probabilidad de cometer un error de tipo II (no rechazar la hipótesis nula cuando en realidad es falsa o no poder demostrar una asociación cuando en realidad existe) se llama beta. Este error será tanto más probable cuanto menor sea el tamaño muestral de nuestro estudio, lo que producirá un aumento del error aleatorio que se traducirá en el cálculo de probabilidades. Como consecuencia, nuestro estudio tendrá poca potencia para encontrar diferencias.
La cantidad (1 – beta) se llama poder. Por lo tanto, el poder estadístico de un estudio es la probabilidad de observar un efecto (de una magnitud especificada) si es que existe uno, lo que se expresará como el complementario de la probabilidad de error tipo II (1-beta).
Distintos procedimientos estadísticos permiten calcular a partir de la hipótesis alternativa (en la que estarán reflejadas las diferencias clínicamente relevantes) cuál es la potencia de un estudio. Si ésta no alcanza al menos un 80% (error tipo II menor del 20%), la potencia de nuestro estudio será insuficiente, debiéndonos plantear una ampliación de la muestra.
6.4 PROBABILIDAD, SIGNIFICACIÓN ESTADÍSTICA E INTERVALOS DE CONFIANZA
6.4.1 Probabilidad
En la ciencia no hay ninguna certidumbre, hay probabilidades. Lo que es cierto acerca de la ciencia es la incertidumbre. En la metodología científica, tratamos de reducir al mínimo la probabilidad de encontrar una asociación cuando en realidad no existe ninguna, y de reducir al mínimo la probabilidad de pasar por alto u omitir una asociación cuando en realidad sí existe.
No podemos eliminar esta probabilidad de error, sin embargo, la estadística analítica puede darnos un cálculo de su magnitud. La probabilidad de cometer un error depende del tamaño de la muestra estudiada para probar la hipótesis de nulidad. Cuanto mayor es el tamaño de la muestra, tanto menos probable será la probabilidad de cometer un error. Esta es la razón por la cual la determinación del tamaño de la muestra es una parte fundamental del diseño de investigación.
6.4.2 Significación estadística
Las pruebas de significación estadística se basan en la lógica y en el sentido común.
Una prueba de significación estadística calcula la probabilidad de que un resultado observado de un estudio, por ejemplo, una diferencia entre dos grupos o una asociación se deba al azar y por consiguiente, de que no pueda obtenerse ninguna inferencia del mismo.
Que una diferencia tenga la probabilidad de ser real y no debida al azar se basa en gran parte en tres criterios:
- Magnitud de la diferencia observada. Es razonable esperar que cuanto mayor sea la diferencia, tanto más probable es que no se deba al azar.
- Grado de variaciones de los valores obtenidos en el estudio. Si los valores se sitúan dentro de un intervalo demasiado amplio, es más probable que las diferencias de las medias se deban a las variaciones del azar.
- Tamaño de la muestra estudiada. Cuanto mayor es el tamaño de la muestra, es más probable que el resultado obtenido refleje los resultados en la población.
Lo que los estadísticos hacen es convertir esta lógica sencilla, mediante las matemáticas, en una fórmula cuantitativa para describir el grado de probabilidad.
Cuando se analizan los datos, fijamos un valor arbitrario para lo que podemos aceptar como alfa o grado de significación estadística. Luego, las pruebas estadísticas determinan el valor P, que es la probabilidad de que una diferencia o una asociación tan grande como la observada puedan haber ocurrido solo por efecto del azar.
Habitualmente, se considera que un resultado tiene poca probabilidad de deberse al azar, o de ser estadísticamente significativo, si el valor P es inferior a 5% (P inferior a 0,05) y se dice que es sumamente significativa si el valor P es inferior a 0,01.
Es importante tener presente que la magnitud de P o la probabilidad de que un resultado se haya producido por el azar depende de dos valores. Estos son la magnitud de la diferencia y el tamaño de la muestra estudiada.
6.4.3 Intervalos de confianza
La significación estadística del resultado nos da una indicación de que era improbable que la diferencia se explicara por el azar. Sin embargo, no nos da una indicación de la magnitud de esa diferencia en la población a partir de la cual se estudió la muestra. Para ello, se ha creado el concepto de intervalo de confianza (IC).
El IC proporciona un intervalo de posibilidades correspondiente al valor de la población y nos permite calcular si las pruebas obtenidas en el estudio son robustas o débiles, y si el estudio es definitivo o se precisarán otros. Si el intervalo de confianza es estrecho, las pruebas obtenidas serán robustas. Un estadístico puede calcular los intervalos de confianza del resultado de casi cualquier prueba estadística.
Cuando se emplea la notificación del intervalo de confianza (IC), se proporciona un cálculo de un punto del resultado, además de un intervalo de valores que son compatibles con los datos y dentro del cual puede esperarse que se sitúe el verdadero valor de la población. Por lo tanto, esto contrasta con la significación estadística, que solo indica si el resultado puede explicarse o no por el azar.
Como en las pruebas estadísticas, los investigadores deben seleccionar el grado de confianza o certidumbre que aceptan que se asocie a un intervalo de confianza. El 95% es la elección más habitual, así como 5% es el grado de significación estadística más usado.
En general, cuando un IC de 95% contiene una diferencia igual a cero, significa que no es posible rechazar la hipótesis de nulidad en el nivel de 5%.
Por ejemplo; Se observa que la concentración de hemoglobina (Hb) parece diferir entre los hombres y las mujeres. En hombres, la concentración media de Hb era de 13,2 g/dl; en las mujeres, el valor era de 11,7 g/dl.
Una prueba de significación estadística basada en un valor P, nos dirá qué probabilidad hay de que esta diferencia sea real o de que sea un resultado de la casualidad. Sin embargo, la prueba estadística no nos dice nada acerca del intervalo de la diferencia que puede esperarse a partir de los datos, entre las concentraciones medias de hemoglobina de los hombres y de las mujeres en la población general, si se obtuviesen y estudiasen otras muestras. En este estudio en particular, la diferencia entre las dos medias es de 1,5 g/dl.
Si, en el ejemplo anterior, el IC correspondiente a la diferencia en la concentración de hemoglobina entre los varones y las mujeres es –0,4 a +3, no podemos rechazar la hipótesis de nulidad de que no hay ninguna diferencia, porque el intervalo de confianza contiene el valor 0.
El IC también es útil para el análisis de la correlación, el coeficiente de correlación (r) se mide en una escala que varía entre +1 y –1, pasando por el 0. La correlación completa entre dos variables se expresa como 1.
En los estudios epidemiológicos nos sirve igualmente para interpretar el riesgo, en un IC mayor del 95% si el intervalo de confianza no incluye en su interior el valor nulo para riesgos (1) interpretamos que el factor estudiado es realmente un factor de riesgo .
6.5 TIPOS DE PRUEBAS DE CONTRASTE DE HIPÓTESIS
Las pruebas de contraste de hipótesis se pueden clasificar en tres tipos según el problema que planteen:
- Pruebas de conformidad; Se determina si los resultados de un estudio están de acuerdo con una teoría preexistente y si un valor o una distribución observada procede de una distribución teórica conocida.
- Pruebas de homogeneidad; Se utilizan al estudiar dos o más muestras para saber si derivan de una misma población.
- Pruebas de relación o de independencia; Se estudian dos o más variables en un mismo individuo con el fin de conocer si las variables están relacionadas entre sí.
Las pruebas de hipótesis también se pueden clasificar en función de la distribución que siguen las variables estudiadas o los estadísticos utilizados. Se diferencian dos tipos de pruebas:
- Pruebas paramétricas; está basada en distribución normal o derivada. Se deben cumplir una serie de condiciones en los parámetros de la población de donde se obtuvo la muestra.
- Pruebas no paramétricas: no hacen ningún supuesto sobre los parámetros de la población.
6.5.1 Comparación de proporciones. Prueba de Jhi cuadrado
Para estudiar la relación entre dos variables cualitativas o categóricas se utiliza la prueba de la Jhi cuadrado o Chi cuadrado.
6.5.2 Comparación de medias. Prueba t de student y análisis de la varianza
Las pruebas de comparación de medias estudian la relación entre una variable categórica y una variable cuantitativa. Las pruebas utilizadas son:
- la t de Student, cuando la variable cualitativa o categórica tiene dos categorías
- el análisis de la varianza (ANOVA), si la variable categórica posee más de dos categorías.
El uso de estas dos pruebas estadísticas obliga a que se cumplan las siguientes condiciones para su aplicación:
- o La muestra debe ser superior a 30 casos (n ≥ 30).
- o Si n > 30, la variable deberá seguir una distribución normal o gaussiana.
Cuando no se cumplen estos criterios, se deben utilizar pruebas o test no paramétricos, como son la U de Mann-Whitney, como alternativa a la t de Student, y el test de Kruskal-Wallis, como alternativa al análisis de la varianza (ANOVA).
6.5.3 Estudio de la relación entre dos variables cuantitativas. Correlación y regresión
Existen dos tipos de análisis para estudiar la relación entre dos variables cuantitativas: la correlación y la regresión lineal.
6.5.4 Análisis de datos apareados
Los datos apareados son aquéllos en los que la misma variable se mide antes y después de una intervención.
Las pruebas estadísticas utilizadas son la prueba de McNemar (comparación de proporciones), la prueba t de Student para datos apareados y el índice kappa (para valorar la concordancia en estudios de reproducibilidad).
6.5.5 Pruebas no paramétricas
Se llaman pruebas no paramétricas aquellas pruebas cuyas hipótesis se formulan independientemente de las distribuciones de probabilidad que sigan las variables, es decir, las variables no cumplen las condiciones de aplicación de las pruebas paramétricas clásicas.
Algunas pruebas no paramétricas se describen en los ejemplos siguientes:
- U Mann Whitney.
- T de Wilcoxon.
- Kruskal Wallis.
- Friedman.
- Coeficiente de correlación de Spearman.
6.5.6 Análisis multivariante
En la investigación no experimental se utilizan técnicas estadísticas que permiten controlar el efecto de otras variables que pudiesen enmascarar una relación causa-efecto. Las herramientas fundamentales para el análisis multivariante son la regresión múltiple y la regresión logística.
PRUEBA A REALIZAR SEGÚN EL TIPO DE VARIABLES DEL ESTUDIO.
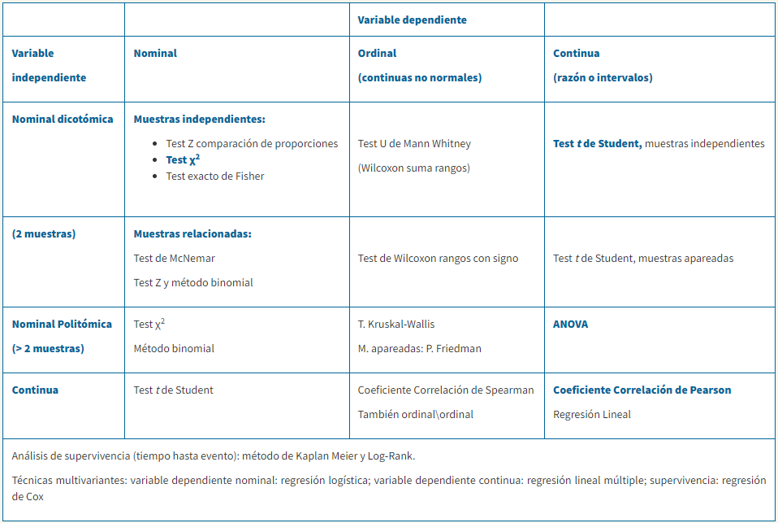
Más información en Contraste de hipótesis
BIBLIOGRAFÍA
- Argimón JM, Jiménez J. Métodos de investigación clínica y epidemiológica. 4º ed. Elsevier España SA. Madrid, 2013.
- Escuela Nacional de Sanidad (ENS) Instituto de Salud Carlos III - Ministerio de Ciencia e Innovación. Miguel Ángel Royo Bordonada, Javier Damián Moreno, “Método epidemiológico”. Madrid: ENS - Instituto de Salud Carlos III, Octubre de 2009
- Castro, A. B. El AEIOU de la investigación en enfermería. Fuden, Salamanca.2013.
- Elena Sinobas P. Manual de investigación cuantitativa para enfermería. Oviedo: Federación de Asociaciones de Enfermería Comunitaria y Atención Primaria; 2011.
- Escuela Nacional de Sanidad (ENS) Instituto de Salud Carlos III - Ministerio de Ciencia e Innovación. Miguel Ángel Royo Bordonada, Javier Damián Moreno, “Método epidemiológico”. Madrid: ENS - Instituto de Salud Carlos III, Octubre de 2009
- Fathalla MF, Fathalla MMF. Guía práctica de investigación en salud. Washington, D.C.: OPS, Of. Regional de la Organización Mudial para la Salud; 2008.
- Hernández Sampieri R, Fernández Collado C, Baptista Lucio P. Metodología de la investigación. 5a ed. México, D.F: McGraw-Hill; 2010. 613 p.
- Mirón Canelo JA, Alonso Sardón M, Iglesias de Sena H. Metodología de investigación en Salud Laboral. Medicina y Seguridad del Trabajo. 2010;56(221):347–65.
- Pineda EB, Alvarado EL de, Hernández de Canales F. Metodología de la investigación: manual para el desarrollo de personal de salud. Washington, D. C.: Organización Panamericana de la Salud?: Organización Mundial de la Salud; 1994.
- Ávila Baray, H.L. (2006) Introducción a la metodología de la investigación Edición electrónica. Texto completo en www.eumed.net/libros/2006c/203/doc. (cita sugerida)
- Bilal U. Belza Mª J.Bolúmar F. Introducción al método epidemiológico y su uso en administración sanitaria[Internet]. Madrid: Escuela Nacional de Sanidad; 2012
- Jarrín Vera I. Conceptos básicos de Estadistica I [Internet]. Madrid: Escuela Nacional de Sanidad; 2012
- Jarrín Vera I. Conceptos básicos de Estadistica II [Internet]. Madrid: Escuela Nacional de Sanidad; 2012
- Pita Fernández, S. Uso de la estadística y la epidemiología en atención primaria. En: Gil VF, Merino J, Orozco D, Quirce F. Manual de metodología de trabajo en atención primaria. Universidad de Alicante. Madrid, Jarpyo Editores, S.A. 1997; 115-161.
- Galindo-Domínguez, H. Estadística para no estadísticos: una guía básica sobre la metodología cuantitativa de trabajos académicos. 1ªed. Alicante:3ciencias, 2020. DOI: https://doi.org/10.17993/EcoOrgyCso.2020.59
- Ochoa Sangrador C., Molina Arias M., Ortega Páez E. Inferencia estadística: contraste de hipótesis. (Internet) Evid Pediatr, 2020; 16:11. Disponible en: https://evidenciasenpediatria.es/articulo/7537/inferencia-estadistica-contraste-de-hipotesis (consultado 20 agosto 2024)