7.1 LA POBLACIÓN DE ESTUDIO
La población o universo es el conjunto de individuos u objetos de los que se desea conocer algo en una investigación. Es la totalidad de individuos o elementos en los cuales puede presentarse determinada característica que va a ser estudiada. Por lo general, no es posible abarcar a toda la población destinataria debido a su elevado número, al costo y al tiempo. En cambio, se estudia a un subconjunto de la población, a partir de la cual se extraen conclusiones (o inferencias), que se aplican a la población destinataria.
El universo debe quedar claramente identificado desde el inicio de la investigación y se debe ser específico al incluir los elementos que forman parte de ella.
En investigación, a esta población de estudio se le conoce como población diana y viene delimitada por características demográficas, sociales, hábitos, problemas de salud, etc.
Dentro de esta población diana se encuentra la población accesible o población de estudio, que es el conjunto de casos que son accesibles para el investigador. Viene determinada por consideraciones prácticas en función de la accesibilidad que tengamos a los sujetos (existencia de registros, circunstancias que faciliten la colaboración, etc.). En la investigación en salud, el consultorio o el hospital puede proporcionar la población accesible. Sin embargo, esta no necesariamente representa a la comunidad, si no a todas las personas que acuden al consultorio o al hospital para el tratamiento de la enfermedad en cuestión. Esto no significa que no deban hacerse estudios realizados en el consultorio o en el hospital. Proporcionan información útil, pero los resultados no deberán presentarse como si reflejaran los correspondientes a todas las personas que padecen la afección.
En la población que realmente vamos a estudiar:
- Los criterios de selección nos definirán a quién estudiaremos.
- El tamaño de la muestra nos dice cuántos individuos necesitaremos.
- El sistema de muestreo que utilizaremos será la forma de obtener la muestra.
- Finalmente, la asignación a los grupos de estudio.
La muestra es el grupo de individuos que realmente se estudiará. Para que se puedan generalizar los resultados tiene que seleccionarse de modo que sea lo más representativa posible de la población destinataria y con una cantidad suficiente para obtener respuestas válidas. El número de individuos de la muestra normalmente se representa por n, y el número de individuos de la población por N.
7.2 LA MUESTRA
La muestra es un subconjunto o parte del universo o población en que se llevará a cabo la investigación con el fin posterior de generalizar los hallazgos. Para generalizar los hallazgos al todo, esa parte que se estudia tiene que ser representativa de la población, es decir, debe poseer las características básicas del todo.
Por ejemplo, si en la población de estudio hay un 55% de mujeres y un 45% de hombres, la muestra deberá aproximarse a esta proporción. Es evidente que la mejor forma de estar seguro de esa representatividad sería estudiando toda la población, sin embargo, esto no siempre es posible o conveniente. En el caso de estar formada por una cantidad ilimitada de unidades, la imposibilidad de estudiarlo todo surge por no conocerse su magnitud.
En general, en la investigación se trabaja con muestras y a pesar de que no hay garantía de su representatividad, hay una serie de ventajas que se pueden destacar:
- Permite que el estudio se realice en menor tiempo.
- Se incurre en menos gastos.
- Posibilita profundizar en el análisis de las variables.
- Permite tener mayor control de las variables a estudiar.
Se tendrán en cuenta los conceptos de validez interna y validez externa, pues de lo contrario queda comprometido el desarrollo del estudio. La validez interna es la validez del propio estudio. Hace referencia a que éste no presente errores y sea desarrollado con el rigor científico necesario, que la muestra sea elegida correctamente, que los criterios de selección sean bien definidos, que sea representativa de la población y de acuerdo a un diseño apropiado.
La validez externa está relacionada con la generalización de los resultados, es decir, con la extrapolación de los resultados de la muestra a la población diana (la muestra debe, para ello, tener las mismas características que la población de origen).
La muestra a seleccionar tiene que ser representativa de esa población para poder hacer generalizaciones válidas. Se estima que una muestra es representativa cuando reúne las características principales de la población en relación a la variable o condición particular que se estudia.
La representatividad de una muestra está dada por su tamaño y por la forma en que el muestreo se ha realizado.
7.3 MUESTREO PROBABILÍSTICO Y NO PROBABILÍSTICO
Lo primero que hay que hacer es definir la unidad de análisis (individuos, organizaciones, periódicos, comunidades, situaciones, eventos, etc.). Aquí el interés se centra en “qué o quiénes”, es decir, en los participantes, objetos, sucesos o comunidades de estudio (las unidades de análisis), lo cual depende del planteamiento de la investigación y de los alcances del estudio.
Ahora bien, generalmente no toda la población accesible será válida para el estudio, por lo que los investigadores deben especificar los criterios que definen quienes deben incluirse y quiénes no. Este proceso de selección va a delimitar a la población elegible.
Los criterios de selección suelen reflejar alguno de los siguientes aspectos:
- Coste: algunos criterios reflejan restricciones de coste. Por ejemplo el acceso a ciertos datos que pueda tener un sobre coste o la disponer de cuestionarios o materiales necesarios para el desarrollo del estudio que pueden ser costosos pueden limitar las posibilidades.
- Problemas de orden práctico: problemas para incluir a personas de difícil acceso geográfico.
- Posibilidad de participar en un estudio: puede ser necesario excluir de un estudio a personas que no puedan complementar un cuestionario.
- Consideraciones de diseño, ya que a veces es adecuado definir una muestra más homogénea para controlar variables extrañas.
Estos criterios, que han de especificarse en el apartado de “material y métodos” del estudio, son de dos tipos:
- Criterios de inclusión (criterios de elegibilidad): especifican las características que la población debe tener. Suelen referirse a las características geográficas y temporales de la población accesible. Implican a veces ciertas concesiones entre los objetivos científicos y los prácticos. Sobre estas y otras decisiones acerca de los criterios de inclusión no hay un solo modo de acción que sea claramente acertado. Lo importante es tomar decisiones sensatas, que quepa utilizar de manera consistente a lo largo del estudio y que proporcionen una base para conocer a quién se le aplica las conclusiones publicadas.
- Criterios de exclusión: define características que sus miembros no deben tener, es decir, indican subgrupos de personas que serían adecuados para la pregunta de investigación si no fuera por características que podrían interferir en el seguimiento, la calidad de los datos o la posibilidad de aceptar la intervención. Una buena norma que preserva el número de posibles participantes en el estudio es tener tan pocos criterios de exclusión como sea posible.
En ocasiones, cuando la población que se estudia es reducida, no es difícil obtener información de todos sus miembros, pero los resultados no podrán aplicarse a ningún otro grupo que no sea el estudiado.
Existen dos grandes tipos de muestreo. Cada uno de ellos ofrece varias formas de extraer muestras de una población. Los dos tipos de muestreo son el Muestreo Probabilístico y el Muestreo No Probabilístico.
7.3.1 Muestreo probabilístico
En el muestreo probabilístico o aleatorio, la muestra es aquella extraída de una población de tal manera que todo miembro de ésta tenga una probabilidad conocida de estar incluido en la muestra. Por lo tanto, conocemos la probabilidad de que un individuo sea elegido para la muestra.
El modelo de selección de la muestra más eficaz es el muestreo probabilístico, en el que cada unidad de muestreo tiene una probabilidad conocida de ser incluido en el estudio. Nos indica cuál es el error de muestreo y dentro de estos el muestreo estratificado es el más preciso.
Los principales tipos de muestro probabilístico son:
- Muestreo aleatorio simple (MAS). Es el más sencillo, eficaz y usado. Otorga a todos los sujetos de una población la misma probabilidad de ser incluidos en la muestra. Tras haber asignado un número a cada sujeto, se utilizan números aleatorios para la obtención de la muestra. Son seleccionados por sorteo o mediante una tabla de números aleatorios que puede ser en formato papel, pero normalmente son generados por ordenador y se utilizan las tablas que incluyen los programas informáticos estadísticos (o la función “ALEATORIO.ENTRE” de la hoja de cálculo ExcelR de Microsoft). Este procedimiento es simple y eficaz, pero tiene un inconveniente, ya que no se puede utilizar si el universo es muy grande.
- Muestreo aleatorio sistemático. Este procedimiento exige, como el anterior, numerar todos los elementos de la población, pero en lugar de extraer n números aleatorios, sólo se extrae uno. Se parte de este número aleatorio i (comprendido 1 yk=coeficiente de elevación, que es un número elegido al azar).Los elementos que integran la muestra son los que ocupan los lugares i, i+k, i+2k, i+3k,..., es decir se toman los individuos de k en k, donde k es el resultado de dividir el tamaño de la población entre el tamaño dela muestra: k=N/n.
Por ej. Tenemos 10000 pacientes en una lista (N) y necesitamos obtener una muestra de 200 (n).
Primero elegimos al azar un paciente entre los 10000/200=50 primeros (supongamos que salga el 25). Por tanto i=25 y k=50
Después, el primer paciente es el que tiene asignado el número 25. El segundo paciente será i+k (25+50=75), el siguiente será el i+2k (25+100=125), y así sucesivamente.
El riesgo de este tipo de muestreo está en los casos en que se dan periodicidades en la población, y sólo obtengamos representantes de una clase o proporciones distintas en la muestra de la que realmente tienen en la población. Esta situación comprometería la representatividad de la muestra.
- Muestreo aleatorio estratificado. Se divide la población en diferentes estratos (grupos homogéneos de sujetos) y se hace un muestreo aleatorio simple dentro de cada estrato, de forma que en la muestra queden representados todos los segmentos que nos interesen. Por ejemplo, si en una población muy heterogénea en cuanto a edad interesa que todos los grupos de edad estén representados, la solución es realizar un muestreo aleatorio simple dentro de cada grupo de edad. A la hora de necesitar este tipo de muestreo, conviene tener en cuenta No hacer muchos estratos y no estratificar con respecto a muchas variables.
- Muestreo por conglomerados. Simplifica el muestreo cuando una población está agrupada en conglomerados (localidades, edificios, manzanas). Se utiliza cuando no se cuenta con un listado detallado de las unidades de la población, y/o se tiene dificultad de organizar las unidades muestrales. En estas circunstancias no podemos utilizar el muestreo estratificado. Por ello se procede a formar grupos o conjuntos de unidades (conglomerados) que los investigadores definen. Se puede elegir a la totalidad de los individuos de un conglomerado o a una muestra aleatoria simple del mismo. Este tipo de muestreo es el menos fiable.
- Por ejemplo, si deseamos conocer el grado de satisfacción de los pacientes con las sesiones de Educación para la Salud, necesitamos una muestra de 1.000 sujetos. Ante la dificultad de acceder individualmente a estos sujetos se decide hacer una muestra por conglomerados. Sabiendo que el número de participantes por Área de Salud han sido 100, los pasos serían los siguientes:
o Recoger un listado de todas las Áreas de Salud.
o Escoger las Áreas de Salud por muestreo aleatorio simple o sistemático.
o Elegir por muestreo aleatorio simple o sistemático los 10 centros (1000/1000=10) que nos proporcionarán los 1000 pacientes que necesitamos.
7.3.2 Muestreo no probabilístico
En el muestreo no probabilístico, “muestreo por conveniencia” o no aleatorio, no se conoce esa probabilidad, y por lo tanto la posibilidad de que existan sesgos es mayor. Eso implica, entre otras cosas, que en principio no se pueden extrapolar los resultados a la población. A pesar de ello, en ocasiones no queda otra elección que utilizarlos.
- Muestreo por cuotas. También denominado en ocasiones “accidental” (no confundir con el muestreo incidental). Se asienta sobre la base de un buen conocimiento de los estratos de la población y/o de los individuos más “representativos” o “adecuados” para los fines de la investigación. Mantiene, por tanto, semejanzas con el muestreo aleatorio estratificado, pero no tiene el carácter de aleatoriedad de aquél. En este tipo de muestreo se fijan unas cuotas que son un número de individuos que reúnen unas condiciones determinadas. Una vez determinada la cuota se eligen los primeros que se encuentren que cumplan esas características. Es el método de elección en las encuestas de opinión. Por ejemplo, necesitamos 120 individuos adictos a drogas de 25 a 40 años, de sexo femenino y residentes en Madrid. Los servicios sociosanitarios de la Comunidad de Madrid proporcionan un listado por núcleos de residencia con todos los sujetos de la Comunidad distribuidos que reúnen esos criterios. Por último, se escogen los primeros de cada listado hasta completar los 120 sujetos que necesitamos.
- Muestreo opinático o intencional. Este tipo de muestreo se caracteriza por un esfuerzo deliberado de obtener muestras “representativas” mediante la inclusión en la muestra de grupos supuestamente típicos. Es muy frecuente su utilización en sondeos preelectorales de zonas que en anteriores votaciones han marcado tendencias de voto.
- Muestreo casual o incidental. Se trata de un proceso en el que el investigador selecciona directa e intencionadamente los individuos de la población. El caso más frecuente de este procedimiento el utilizar como muestra los individuos a los que se tiene fácil acceso (los profesores de universidad emplean con mucha frecuencia a sus propios alumnos) o el caso particular de los voluntarios.
- Cadena o bola de nieve. Se localiza a algunos individuos, los cuales conducen a otros, y estos a otros, y así hasta conseguir una muestra suficiente. Este tipo se emplea frecuentemente cuando se hacen estudios con poblaciones “marginales”, delincuentes, sectas, pacientes de difícil localización por su “marginalidad”, etc.
7.4 CÁLCULO DE UNA MUESTRA REPRESENTATIVA
La determinación del tamaño de la muestra tiene por objeto conocer cuál es el número mínimo de sujetos o unidades de análisis necesarias para nuestro propósito. Por lo tanto, el tamaño muestral hace referencia al número de elementos de la población que hay que seleccionar para extraer de ella la información que después se va a generalizar
Según Fisher, el tamaño de la muestra debe definirse partiendo de dos criterios:
- Los recursos disponibles, que fijan el tamaño máximo de la muestra. La recomendación es siempre tomar la muestra mayor posible. La lógica nos indica que entre más grande sea esta, mayor posibilidad tendrá de ser más representativa y menor será el error de muestreo, el cual siempre existe.
- Los requerimientos del plan de análisis que fija el tamaño mínimo de la muestra. El tamaño de la muestra deberá ser suficiente para permitir un análisis confiable de los cruces de variables, para obtener el grado de precisión requerido en la estimación de proporciones, y para probar si las diferencias entre proporciones son estadísticamente significativas. Esto significa que al momento de decidir el tamaño de la muestra es necesario tener presente el tipo de cuadros que se elaborarán y las técnicas estadísticas que se emplearán.
Cuando se hace una muestra probabilística, los investigadores deben preguntarse sobre el número mínimo de unidades de análisis (personas, organizaciones, historias clínicas, etc.), que necesito para conformar una muestra (n) que me asegure un error estándar aceptable fijado por el equipo investigador, dado que la población N es aproximadamente de tantos elementos.
Cuanto más homogénea sea la población, su varianza (variabilidad) será más pequeña y por lo tanto, el tamaño maestral que tenemos que elegir será menor. También, a mayor nivel de confianza y precisión (menor error muestral tolerado), más muestra será necesaria. Varianza, nivel de confianza y error muestral están directa y positivamente relacionados.
El tamaño de la muestra variará en función del método de muestreo escogido, dependiendo la elección de la finalidad (que vendrá determinada por los objetivos). Se utilizarán diferentes fórmulas si se pretende estimar una proporción, estimar una media, comparar dos proporciones y comparar dos medias. Al hacer el cálculo final del tamaño de la muestra, deben tenerse también en cuenta los factores como los abandonos, el desgaste y las pérdidas en el seguimiento.
Para calcular el tamaño tenemos que conocer si tratamos de poblaciones finitas o infinitas.
7.4.1 Tamaño muestral para poblaciones infinitas
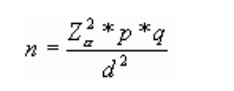
Donde:
n = El tamaño de la muestra que queremos calcular
N = Tamaño de la población
Z = Es la desviación del valor medio que aceptamos para lograr el nivel de confianza deseado. En función del nivel de confianza que busquemos, usaremos un valor determinado. Los valores más frecuentes son:
- Nivel de confianza 90% -> Z=1,645
- Nivel de confianza 95% -> Z=1,96
- Nivel de confianza 99% -> Z=2,575
e = Es la precisión o el margen de error máximo que admito (se puede representar también como d)
p = Es la proporción que esperamos encontrar. Como regla general, usaremos p=50% si no tengo ninguna información sobre el valor que espero encontrar. (p= 0.5)
Ejemplo: ¿a cuántas personas tendríamos que estudiar para conocer la prevalencia de diabetes?
n = 1,962 x 0,05 x 0,95 / 0,032 = 202
En el ejemplo, determinamos una seguridad del 95%, una precisión (e) del 3%, y una proporción esperada del 5%. Asumimos que puede ser próxima al 5%, si no tuviésemos ninguna idea utilizaríamos el valor de p=0,5 (50%) que maximiza el tamaño muestral.
7.4.2 Tamaño muestral para poblaciones finitas
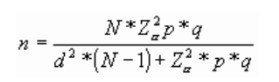
En el ejemplo anterior ¿A cuántas personas tendría que estudiar de una población de 15.000 habitantes para conocer la prevalencia de diabetes?
n = 15.000 x 1,962 x 0,05 x 0,95 / 0,032 x (15.000-1) + 1,962 x 0,05 x 0,95 =207
- Con el programa "Epi Info 3.5.4" un programa de software gratis del dominio público desarrollado por los Centros para el Control y la Prevención de Enfermedades de los Estados Unidos (CDC) descarga gratuita aquí: https://www.cdc.gov/epiinfo/esp/es_index.html
- Fisterra(descarga): https://www.fisterra.com/mbe/investiga/9muestras/tamano_muestral.xls
- Programa online gratuito GRANMO
La tendencia de los investigadores que se inician es querer aplicar una fórmula que indique cuál será el número de sujetos que deben incluir en la muestra. Sin embargo, no es esto lo más importante. Una muestra, probabilística o no, dependerá de muchos aspectos como los recursos disponibles, la heterogeneidad de las variables y sujetos a estudiar, la técnica que se emplee en el muestreo, el tipo de análisis que se utilizará, el grado de precisión que deben tener los datos, entre otros.
7.4.3 Asignación a los grupos de estudio
La asignación de los individuos a los diferentes grupos debe asegurar la comparabilidad de los grupos, es decir, que no haya diferencias entre las variables generales.
La asignación según el tipo de estudio es:
- Estudios de casos y controles. La asignación se realiza en función de la existencia o no de enfermedad.
- Estudios de cohortes. La asignación se realiza en función de la presencia o no de exposición.
- Estudios experimentales. La más utilizada es la asignación aleatoria o randomización.
Asignación Aleatoria al grupo de tratamiento o al grupo control
La aleatorización es una de las formas de evitar los sesgos de selección. Su propósito es posibilitar las comparaciones en los grupos de asignación de los tratamientos. Su principal ventaja está en que permite enmascarar a los pacientes en la asignación de tratamiento antes del inicio del ensayo clínico, de manera que no se sepa ni quiénes son los pacientes, ni en qué orden aparecen, ni qué tratamiento se les asigna.
Cada participante tendrá una probabilidad conocida y fijada de antemano de recibir la intervención o el placebo. Su función principal es conseguir la mayor imparcialidad posible al asignar la intervención y el control. La asignación aleatoria o randomización consigue que, con muestras suficientemente grandes, las características de ambos grupos tiendan a ser iguales, con lo que las variables que pudieran interferir (o confundir) en los resultados, conocidas o fundamentalmente desconocidas, se distribuyan con la misma probabilidad en ambos grupos. De esta forma, los resultados que se encuentren tras la intervención se deberán a ésta y no a las diferencias que inicialmente existen entre los grupos. La randomización, por tanto, facilita la realización de inferencias causales en relación con las intervenciones estudiadas.
BIBLIOGRAFÍA
- Argimón JM, Jiménez J. Métodos de investigación clínica y epidemiológica. 4º ed. Elsevier España SA. Madrid, 2013.
- Escuela Nacional de Sanidad (ENS) Instituto de Salud Carlos III - Ministerio de Ciencia e Innovación. Miguel Ángel Royo Bordonada, Javier Damián Moreno, “Método epidemiológico”. Madrid: ENS - Instituto de Salud Carlos III, Octubre de 2009
- Castro, A. B. El AEIOU de la investigación en enfermería. Fuden, Salamanca.2013.
- Elena Sinobas P. Manual de investigación cuantitativa para enfermería. Oviedo: Federación de Asociaciones de Enfermería Comunitaria y Atención Primaria; 2011.
- Escuela Nacional de Sanidad (ENS) Instituto de Salud Carlos III - Ministerio de Ciencia e Innovación. Miguel Ángel Royo Bordonada, Javier Damián Moreno, “Método epidemiológico”. Madrid: ENS - Instituto de Salud Carlos III, Octubre de 2009
- Fathalla MF, Fathalla MMF. Guía práctica de investigación en salud. Washington, D.C.: OPS, Of. Regional de la Organización Mudial para la Salud; 2008.
- Hernández Sampieri R, Fernández Collado C, Baptista Lucio P. Metodología de la investigación. 5a ed. México, D.F: McGraw-Hill; 2010. 613 p.
- Mirón Canelo JA, Alonso Sardón M, Iglesias de Sena H. Metodología de investigación en Salud Laboral. Medicina y Seguridad del Trabajo. 2010;56(221):347–65.
- Pineda EB, Alvarado EL de, Hernández de Canales F. Metodología de la investigación: manual para el desarrollo de personal de salud. Washington, D. C.: Organización Panamericana de la Salud?: Organización Mundial de la Salud; 1994.
- Ávila Baray, H.L. (2006) Introducción a la metodología de la investigación Edición electrónica. Texto completo en www.eumed.net/libros/2006c/203/doc. (cita sugerida)
- Bilal U. Belza Mª J.Bolúmar F. Introducción al método epidemiológico y su uso en administración sanitaria[Internet]. Madrid: Escuela Nacional de Sanidad; 2012
- Jarrín Vera I. Conceptos básicos de Estadistica I [Internet]. Madrid: Escuela Nacional de Sanidad; 2012
- Jarrín Vera I. Conceptos básicos de Estadistica II [Internet]. Madrid: Escuela Nacional de Sanidad; 2012
- Pita Fernández, S. Uso de la estadística y la epidemiología en atención primaria. En: Gil VF, Merino J, Orozco D, Quirce F. Manual de metodología de trabajo en atención primaria. Universidad de Alicante. Madrid, Jarpyo Editores, S.A. 1997; 115-161.
- Galindo-Domínguez, H. Estadística para no estadísticos: una guía básica sobre la metodología cuantitativa de trabajos académicos. 1ªed. Alicante:3ciencias, 2020. DOI: https://doi.org/10.17993/EcoOrgyCso.2020.59
- Ochoa Sangrador C., Molina Arias M., Ortega Páez E. Inferencia estadística: contraste de hipótesis. (Internet) Evid Pediatr, 2020; 16:11. Disponible en: https://evidenciasenpediatria.es/articulo/7537/inferencia-estadistica-contraste-de-hipotesis (consultado 20 agosto 2024)